Digest: Editor Internals - MS Word
Posted on by Jethro Kuan
Recently, I delivered a presentation on techniques that enable real-time collaboration, with a focus on text editors. Since, I’ve developed an interest in how text editors are implemented. This series is an attempt at an overview of the internals of all popular text editor implementations (including, but not exhaustively: MS Word, Vim, Emacs and Atom).
The implementations I present are far from an exhaustive list of all possible text editor implementations. Simpler implementations can be easily conjured (eg. simply represent the text as an array of characters). However, these naive implementations are inefficient, and never found in product-ready text editors, and are hence not discussed.
Abstracting the text editor
Before any discussion about text editors is made, we need to define a few terms. An item is the data type in question. In most implementations, the item refers to an ASCII character. A text editor maintains a sequence (ordered set) of items. The position of an item is the index of the sequence which identifies the item (usually 0-indexed).
All operations on a text editor can be derived from the following primitive operations:
Empty(): Create a new empty sequenceInsert(seq, pos, i): Insert new itemiat positionposin sequenceseq.Delete(seq, pos): Delete the item at positionposin sequenceseq.ItemAt(seq, pos): Returns the item at positionposin sequenceseq.
Compound operations such as pasting (multiple inserts) can be obtained with a combination of these operations.
Buffers, Spans and Descriptors
A buffer is a set of sequentially addressed memory locations. Think of it as a slice of memory (although not technically correct, it happens to be true with regards to text editors). This sequence of memory locations do not have to correspond to that of the sequence. For example, the sequence “abc” need not be represented as “abc” in the buffer. In the scenario where both the buffer and the sequence are logically contiguous, we call it a span. Descriptors are simply pointers to these spans.
Because many text implementations require buffers to be able to grow infinitely large, buffers tend to be stored in disk files, rather than in memory.
Piece Table
We start our journey by looking at piece tables, found in early versions of Microsoft Word, and Abiword, the document editor I swore by several years ago. Both Abiword and MS Word use an in-RAM piece table.
Implementation
The piece table uses two buffers. The first buffer is called the file buffer, and contains the original contents of the file, and is read only; the second buffer is called the add buffer, and is a dynamically-sized buffer that is append-only.
The sequence starts off as one big span, and is subsequently divided into smaller spans after several editor operations.
The piece table is implemented as a doubly-linked list, often with sentinel nodes at the head and tail. The choice of a doubly-linked list is because of its simplicity, and is not the only data structure compatible with piece tables.
While pieces contain no text; they contain information about the text object it represents. Specifically, piece objects store the start, end and buffer ID, and all together they identify a span in the sequence.
struct piece
{
piece * next;
piece * prev;
size_t start;
size_t length;
size_t buffer;
};
It follows from this design that pieces don’t know their logical position in the sequence. They only know the physical location of the data they represent, and this makes insertion and deletion quick. It does, however, suffer from the same limitations of a doubly-linked list: There is no way to directly access a specific text-offset within the document. This issue is circumvented if a tree structure were to be used instead of a linked list. All this will be clear in the next section, where the piece table is put to the test.
Initializing a piece table
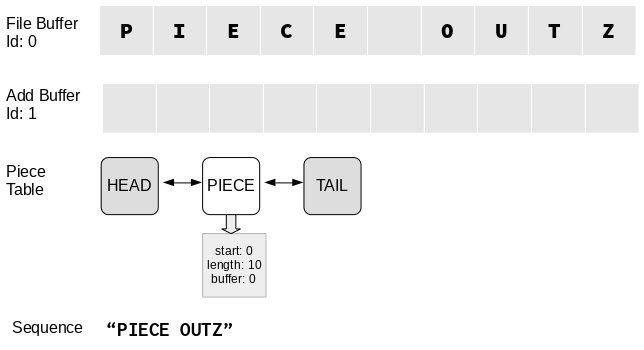
We start off by opening our file, containing the text “piece outz”.
This creates a read-only file buffer containing the ten characters, and an empty add buffer of arbitrary size.
Empty() is called, creating a doubly-linked list with just the sentinel
head and tail nodes. A span is then created, which represents the
entirety of the file buffer contents. This span is appended to the
linked list.
Removing text
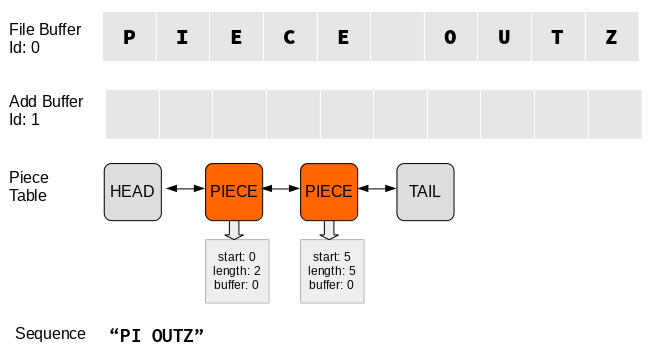
Suppose we want to change the text from “piece outz” to “pizza outz”. First, we’d have to remove 3 characters “ece”.
Here, the original big span is split into two. The two spans represent, respectively:
- The items before the delete (in this case “PI”)
- The items after the delete (in this case " OUTZ")
In general, the delete operation increases the number of spans in the piece table by 1.
Insert text
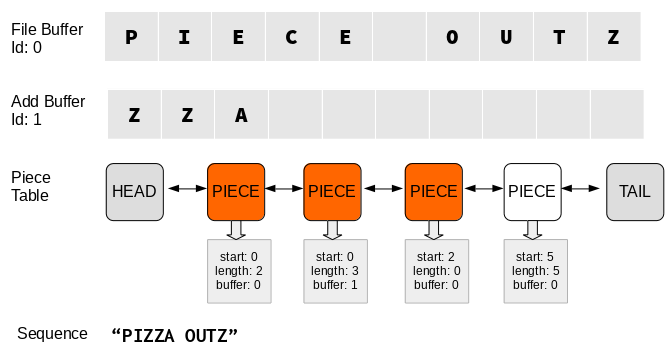
Now, we have to insert the characters “zza” in the correct position. Note that if several items are inserted in a row, the items are combined into a single span. These characters are first appended to the add buffer. Next, the span is split into 3:
- The first span represents the items of the old span before the insert. (“PI”)
- The second span represents the inserted items (“ZZA”)
- The third span represents the items of the old span after the insert ("")
Advantages
Notice that the original file is read-only; this is friendly for caching. Also, everything is append-only, lending itself to cheap undos by smartly storing previous descriptors.
In addition, text editors like MS Word require the storage of formatting information. This is trivial, since appended text in the add-buffer never changes its memory address, and can be safely refered to with pointers.
The size of the piece table is a function of the number of insert and delete operations, and not the size of the file, which makes this ideal for editing large files.
Disadvantages
The idea behind the piece table I described in this article is simple. Implementation, however, can get unwieldy, and is certainly lengthier than other data structures. The versatility of piece tables lend themselves to the availability of a whole host of optimizations, which tend to end up as a huge ball of mud.
Modern text editors seldom implement piece tables underneath. Piece tables were invented some 30 years ago, in an era of limited memory and slow CPUs. Computers then were unable to handle less efficient sequence data structures, such as arrays of lines as spans. These archaic data structures power Vim and Emacs, and no one’s complaining about the editors being slow. This, however, is an article for another day.
In the next article of this series I’ll be covering Emacs and some of the common misconceptions surrounding it.